.png)
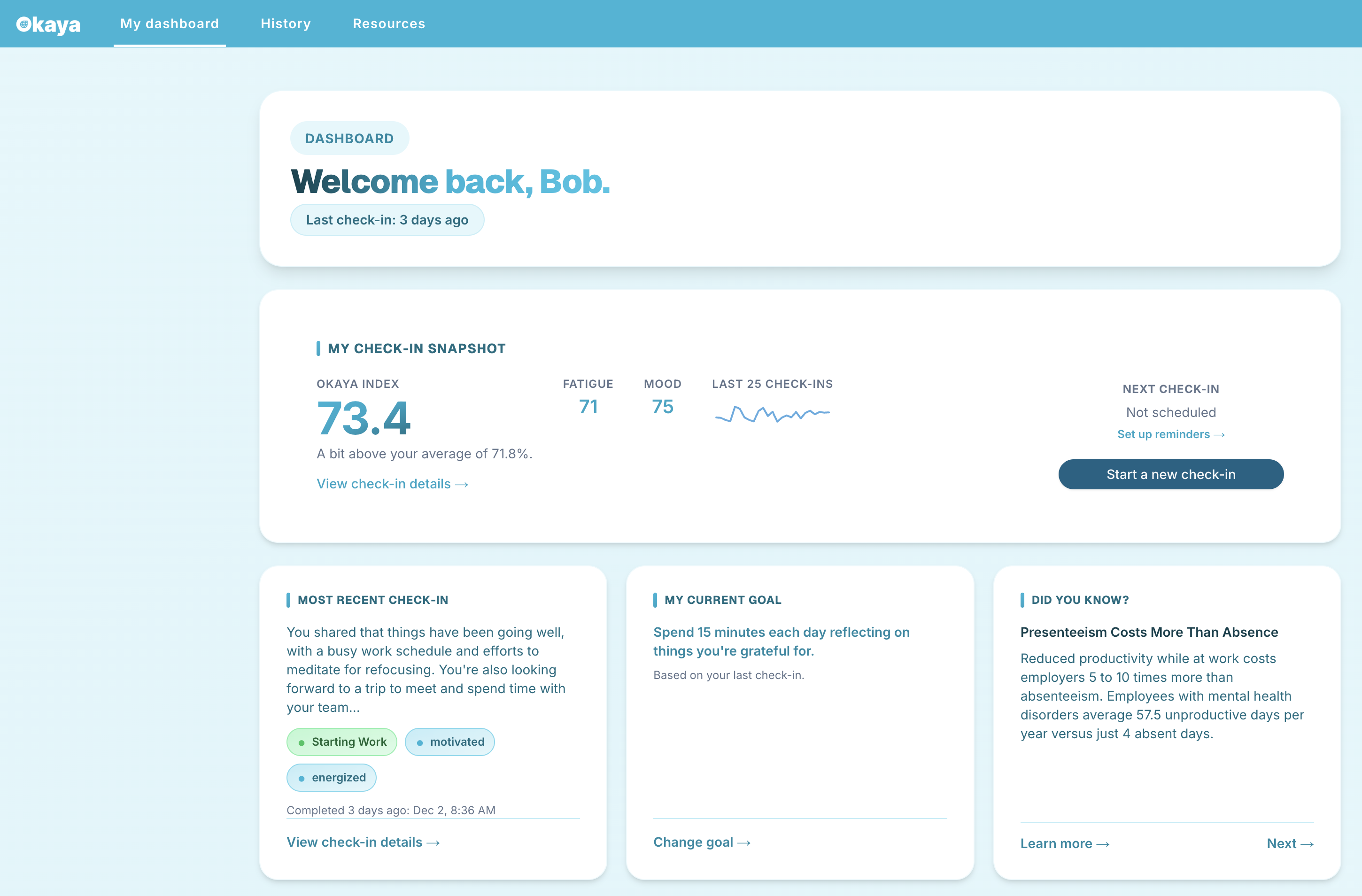
Okaya tells you in 3 minutes.
A video check-in that reads your facial expressions, voice patterns, and language to detect when fatigue or stress is affecting your readiness — before it affects your performance.
🔒 Your data is 100% private and encrypted.







Okaya is an AI-powered readiness platform that uses brief video check-ins to analyze facial expressions, voice patterns, and language — producing a personal cognitive and emotional readiness score in under 3 minutes. Built for first responders, military operators, pilots, and high-performance teams. No wearables. No surveys. No video stored. SBIR-funded by the US Air Force.


You're trained to push through; that's the problem. Okaya catches the drift you can't see: fatigue, stress, cognitive load. Track your baseline. Spot early warning signs. Stay sharp.
Your people won't always tell you when they're struggling. Okaya gives you anonymized crew dashboards; trends by shift, station, or unit. Objective data for scheduling and staffing. Individual scores stay private.
Embed cognitive readiness scoring directly into your app or platform. Real-time risk signals. Privacy-first architecture. Built for high-stakes environments.
Learn morePush through. Wait until something breaks. Try the EAP nobody uses. Hope someone speaks up — knowing nobody will.
See where they're at before anyone else has to ask. Notice the drift early. Keep it private. Decide what it means.
Step 1: Talk to our AI assistant (3 min) on any device.
Step 2: We analyze what you can't see: Face (fatigue, mood), voice (stress, cognitive load), language (mental sharpness). No video stored.
Step 3: Get your Okaya Score: A readiness score compared to YOUR baseline; not a generic average. Track trends over time.
Okaya reveals anonymous patterns in cognitive load, stress response, and mental state before they impact performance.
What It's NOT:
❌ A replacement for professional or peer support
❌ A tracking device for your department
❌ A diagnostic or medical tool
What It IS:
✅ A private tool to monitor readiness
✅ Objective data that reveals patterns over time
✅ Operational data for budget optimization
.png)
Our power users know that Okaya's insights can help them stay at their best for themselves, their teams, and their loved ones.



.png)
Our FAQ has been compiled from the most commonly asked questions we have received. You can also learn more about our technology by downloading our white paper.

Okaya serves three groups: (1) Individual high-performers — firefighters, pilots, military operators, athletes — who want to track their own readiness. (2) Team leaders who need anonymized visibility into crew readiness trends without accessing individual data. (3) Developers and platform operators who want to embed readiness scoring via Okaya’s API.
Okaya is an AI-powered readiness platform that delivers real-time assessments through brief video check-ins. By analyzing facial expressions, voice patterns, and language, Okaya produces a personalized readiness score — the Okaya Score. This helps individuals monitor their cognitive and emotional state and assists organizations in spotting early signs of fatigue and burnout, all while maintaining user privacy.
The Okaya Score is a personalized readiness score generated from a 3-minute video check-in. It combines data from facial expressions, voice tone, and spoken words to assess your cognitive and emotional state relative to your personal baseline. The process is entirely encrypted, and you retain full control over your data.
User data security is a top priority for Okaya. The platform employs end-to-end encryption and follows industry leading standards. All data is anonymized, and no personal identifiers are shared, ensuring that individuals' privacy is maintained.
Yes. Okaya’s API lets technology providers and organizations embed readiness assessments directly into their own platforms. The API uses computer vision and voice analysis to evaluate cognitive and emotional readiness from brief video check-ins, returning structured readiness scores that integrate with scheduling, EHR, and operational systems.
Absolutely. Users have full control over their data and can choose to share their Okaya Score and related insights with therapists or other professionals. This feature enables individuals to seek targeted support when needed, enhancing the collaborative aspect of mental health care.
Okaya offers support for organizations looking to implement the platform, including access to product demos and resources to facilitate integration. You can request a demo to understand how Okaya can be tailored to your specific needs and receive guidance on setup and deployment.


